Pig est un outil, développé initialement par Yahoo vers 2006, destiné à être une interface de haut niveau pour un système hadoop. Pig propose un langage de programmation de haut niveau, appelé Pig Latin (du nom d’un argot anglais, analogue au louchébem en français), qui permet un accès aux données par des techniques comparables à celles de SQL.
Une des applications principales de Pig est le processus ETL (Extract Transform Load) : une société de services web extrait des logs de ses serveurs web des informations de connexion de se ses clients, nettoie les données et effectue des opérations d’agrégation avant de charger ces données sur système de traitement de l’information NoSQL.
La philosophie de Pig
Les développeurs de pig décrivent leur philosophie de la façon suivante :
Pigs Eat Anything
Pig can operate on data whether it has metadata or not. It can operate on data that is relational, nested, or unstructured. And it can easily be extended to operate on data beyond files, including key/value stores, databases, etc.
Pigs Live Anywhere
Pig is intended to be a language for parallel data processing. It is not tied to one particular parallel framework. It has been implemented first on Hadoop, but we do not intend that to be only on Hadoop.
Pigs Are Domestic Animals
Pig is designed to be easily controlled and modified by its users.
Pig allows integration of user code where ever possible, so it currently supports user defined field transformation functions, user defined aggregates, and user defined conditionals. These functions can be written in Java or scripting languages that can compile down to Java (e.g. Jython). Pig supports user provided load and store functions. It supports external executables via its stream command and Map Reduce jars via its mapreduce command. It allows users to provide a custom partitioner for their jobs in some circumstances and to set the level of reduce parallelism for their jobs. command. It allows users to set the level of reduce parallelism for their jobs and in some circumstances to provide a custom partitioner.
Pig has an optimizer that rearranges some operations in Pig Latin scripts to give better performance, combines Map Reduce jobs together, etc. However, users can easily turn this optimizer off to prevent it from making changes that do not make sense in their situation.
Pigs Fly
Pig processes data quickly. We want to consistently improve performance, and not implement features in ways that weigh pig down so it can’t fly.
Un exemple pour comparer les programmations en pig et en SQL
L’exemple suivant est proposé par des personnes liées au développement de Pig, et donc légèrement partiales.
On imagine des données stockées dans trois tables, soit sous forme de table d’un SGBDR, soit sous forme de fichiers texte :
-
usersdéfinissant des individus, avec les champs :name,age,ipaddr -
clicksenregistrant des clicks sur des URL, avec les champsuser,url,value(valeur numérique strictement positive si c’est une vraie connexion) -
geoinfoavec des champsipaddretdma, associant à des adresses IP des zones géographiques, désignées par l’identifiant numériquedma.
On veut extraire de ces données le nombre de vraies connexions par zone géographique et stocker le résultat dans une nouvelle table.
En SQL
insert into ValuableClicksPerDMA
select dma, count(*) from geoinfo
join
( select name, ipaddr from users join clicks on (users.name = clicks.user) where value > 0; )
using ipaddr
group by dma;Avec Pig
Users = LOAD ’users’ AS (name, age, ipaddr);
Clicks = LOAD ’clicks’ AS (user, url, value);
ValuableClicks = FILTER Clicks BY value > 0;
UserClicks = JOIN Users BY name, ValuableClicks BY user;
Geoinfo = LOAD ’geoinfo’ AS (ipaddr, dma);
UserGeo = JOIN UserClicks BY ipaddr, Geoinfo BY ipaddr;
ByDMA = GROUP UserGeo BY dma;
ValuableClicksPerDMA = FOREACH ByDMA GENERATE group, COUNT(UserGeo);
STORE ValuableClicksPerDMA INTO ’ValuableClicksPerDMA’;Pig décrit un processus, constitué d’opérations élémentaires, qui s’enchainent dans un pipeline. On parle de langage de "dataflow".
Si on veut stocker une donnée intermédiaire, on rajoute une ligne :
Users = LOAD ’users’ AS (name, age, ipaddr);
Clicks = LOAD ’clicks’ AS (user, url, value);
ValuableClicks = FILTER Clicks BY value > 0;
UserClicks = JOIN Users BY name, ValuableClicks BY user;
Geoinfo = LOAD ’geoinfo’ AS (ipaddr, dma);
UserGeo = JOIN UserClicks BY ipaddr, Geoinfo BY ipaddr;
STORE UserGeo INTO ’UserGeoIntermediate’;
ByDMA = GROUP UserGeo BY dma;
ValuableClicksPerDMA = FOREACH ByDMA GENERATE group, COUNT(UserGeo);
STORE ValuableClicksPerDMA INTO ’ValuableClicksPerDMA’;Un deuxième exemple montre comment un pipeline peut se séparer en plusieurs branches :
On a des données d’utilisateurs stockées dans users, des données sur les achats stockées dans Purchases.
Pour lancer une campagne publicitaire ciblée, on veut déterminer d’une part les régions (déterminées par leur numéro zip) où il y a eu des achats très importants, et d’autre part les types scocilogiques (age + sexe) pour lesquels les achats sont plus importants.
Users = LOAD ’users’ AS (name, age, gender, zip);
Purchases = LOAD ’purchases’ AS (user, purchase_price);
UserPurchases = JOIN Users BY name, Purchases BY user;
GeoGroup = GROUP UserPurchases BY zip;
GeoPurchase = FOREACH GeoGroup GENERATE
group, SUM(UserPurchases.purchase_price) as sum;
ValuableGeos = FILTER GeoPurchase BY sum > 1000000;
STORE ValuableGeos INTO ’BYzip’;
DemoGroup = GROUP UserPurchases BY (age, gender);
DemoPurchases = FOREACH DemoGroup GENERATE
group, SUM(UserPurchases.purchase_price) as sum;
ValuableDemos = FILTER DemoPurchases BY sum > 100000000;
STORE ValuableDemos INTO ’BYagegender’;Présentation rapide de Pig
Généralités
-
Pig (ou plutôt le langage de programmation Pig Latin) est un langage de DataFlow :
-
On décrit un flux de données.
-
Le compliateur PIG traduit ceci en un graphe orienté acyclique (directed acyclic graph : DAG) d’opérations.
-
Ces opérations sont ensuites traduites en opérations map-reduce de façon transparente pour l’utilisateur.
-
-
Pig peut s’utiliser de différentes façons :
-
En mode local :
pig -x local -
Dans un cluster Hadoop :
pig -x mapreduce.
-
-
on peut travailler de plusieurs façons :
-
en ligne de commandes (avec l’interpréteur
grunt) pour mettre au point. C’est l’équivalent de ce qu’on fait dans le terminal demysql. Voici un exemple de session :
-
pig -x local
grunt> records = load ’texte’ using TextLoader;
2018-12-04 10:01:11,713 [main] INFO org.apache.hadoop.conf.Configuration.deprecati
grunt> dump records;
2018-12-04 10:01:54,706 [main] INFO org.apache.pig.backend.hadoop.executionengine.
(salut les copains)
grunt>-
ou bien programmation dans un fichier. On commence par créer une fichier
monfichier.pigcontenant
Users = LOAD ’users’ AS (name, age, ipaddr);
Clicks = LOAD ’clicks’ AS (user, url, value);
et encore des tas d’autres lignes, toutes terminées par ";".puis on exécute ce fichier en tapant pig -x local monfichier.pig
De Pig à MapReduce
Le moteur de Pig traduit le plan logique décrit par l’utilisateur en un enchainement d’opérations Map et Reduce, qui sont ensuite réalisées par le moteur Hadoop :
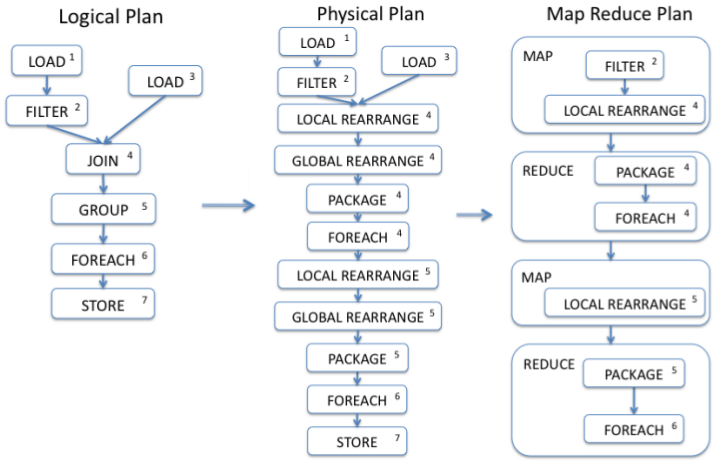
Le langage Pig Latin
On manipule des relations, comme en SQL, et chaque ligne est une instruction prenant en entrée une relation (table) et rendant une nouvelle relation. Elle prend la forme
table_sortie = INSTRUCTION table_entree PARAMETRES ;Quelques commandes d’entrée-sortie :
Il y a des opérations un peu différentes :
-
LOADpour charger des données externes et les mettre dans une relation
Etant donné un fichier fichier.csv contenant plusieurs champs, séparées par des virgules, on le charge dans une relation par :
personnes = LOAD ’fichier.csv’ USING PigStorage(’,’)
AS (id:int, nom:chararray, prenom:chararray, age:int, taille:float);Ici PigStorage est un driver d’entrée-sortie, de même que JsonLoader ou TextLoader.
-
DUMPpour afficher le contenu d’une relation à l’écran (pour le débogage) -
SAMPLEqui affiche seulement un échantillon de la relation (plus pratique queDUMP) -
STORE pour enregistrer le contenu d’une relation dans un fichier.
STORE nom_table INTO 'fichier.csv' USING PigStorageRelations et types :
Une relation est une collection de n-uplets, ayant des types définis :
-
entiers int ou long
-
réels float ou double
-
chaînes chararray ou objets binaires bitearray
Une relation a un schéma, de la forme :
(id:int, nom:chararray, prenom:chararray, age:int, taille:float)Schémas complexes :
Des schémas composés existent aussi : des tuples et des sacs (bag).
segments = LOAD ’segments.csv’ AS (
nom:chararray,
P1:tuple(x1:float, y1:float),
P2:tuple(x2:float, y2:float));ou
polygones = LOAD ’polygones.csv’ AS (
nom:chararray,
Points:{tuple(x:float, y:float)}));Instructions ORDER et LIMIT :
tripartaille = ORDER personnes BY taille DESC;
dixplusgrands = LIMIT tripartaille 10;Instruction FILTER :
ados = FILTER personnes BY age > 12 AND age < 18 ;Instruction FOREACH GENERATE :
C’est en gros l’équivalent d’un SELECT en SQL, et cela sert à faire des opération de projection.
taille_ados = FOREACH ados GENERATE prenom, taille*100 as taille_cm ;rendra des champs
(marc, 163)
(eloise, 175)
(antoine,163)et le deuxième champ sera accessible par le nom taille_cm.
Autre exemple : on charge un gros fichier de données, puis on veut en extraire juste les colonnes qui nous intéresseront par la suite :
donnes_brutes = LOAD 'gros_fichier' USING PigStorage(',') ;
donnees_extraites = FOREACH donnees_brutes GENERATE
$0 AS nom ,
$4 AS salaire ,
$2 AS num_secu ;Instruction GROUP BY
ados_par_taille = GROUP taille_ados BY taille_cm ;rendra
(163,{(marc,163),(antoine,163)})
(175,{(eloise, 175)})Il s’agit d’une nouvelle relation, composée de couples. Le nom du premier champ de ces couples sera toujours group, et celui du second champ sera celui de la relation donnée en entrée (ici
taille_ados).
On accède donc dans notre cas aux champs par ados_par_taille.group et ados_par_taille.taille_ados.
On dispose aussi de l’argument ALL qui permet de regrouper tous les n-uplets dans un seul sac :
ados_par_taille = GROUP taille_ados ALL ;on obtient ainsi :
(all,{(marc,163),(antoine,163),(eloise, 175)})L’instruction GROUP BY est utilisée avec des fonctions d’agrégation qui sont appliquées dans un FOREACH.
Imaginons une table décrivant des prestations effectuées par différentes personnes et donnant lieu chacune à une rémunération. On veut savoir combien chaque personne a touché d’argent :
remunerations_groupees = GROUP prestations BY nom ;
remunerations_total = FOREACH remunerations_groupees GENERATE
group AS nom,
SUM(remunerations_groupees.remuneration) AS somme_totale ;On dispose de plusieurs fonction d’agrégation : SUM, AVG, COUNT, MAX, MIN.
Jointure avec l’instruction JOIN :
A partir de deux relations, on obtient une nouvelle relation.
nouvelle_relation = JOIN rel1 BY champ1, rel2 BY champ2;C’est le résultat obtenu en SQL par
SELECT * FROM rel1, rel2 WHERE rel1.champ1 = rel2.champ2;Un exercice de traitement de données
L’archive https://math.univ-angers.fr/~ducrot/bigdata/driver_data.tgz contient trois fichiers csv décrivant les affaires d’une société de transport :
-
drivers.csv: information nominale sur les chauffeurs -
truck_event_text_partition.csv: recense chaque événement concernant les camions -
timesheet.csv: enregistre les temps de parcours et le nombre de miles parcourus
A partir de ces fichiers, on veut obtenir une table affichant en face de chaque nom de chauffeur :
-
son adresse,
-
son nombre total d’heures de conduite,
-
son nombre total de miles parcourus,
-
le nombre d’événement anormaux qui lui sont attribués.
La table sera classée par ordre alphabétique de nom de chauffeur.
Le résultat sera enregistré dans un fichier texte.
Pour comparer, on va faire la même opération en utilisant pandas pour charger les données dans des DataFrames, puis en
-
effectuant un traitement direct avec pandas
-
chargeant les DataFrames dans une base sqlite, et en appliquant des commandes SQL à la base de données.
On rappelle ici comment pandas permet de charger un fichier dans un DataFrame, et comment il permet d’envoyer ce DataFrame dans une table d’une base de données relationnelle :
import pandas, sqlite3
### Chargement d'un ficheir csv dans un DataFrame pandas
colonnes=[...] # liste des noms de colonnes
df = pandas.read_csv("fichier", sep=..., names=colonnes)
### import des données de pandas dans une base relationnelle, par exemple sqlite
connexion = sqlite3.connect("mabase.db") # crée la base si elle n’exite pas déjà
df.to_sql("table1",connexion) # charge le dataframe dans la table "table1" de "mabase"
connexion.close()Programmer le wordcount avec Pig
Programmer le wordcount en pig suit la logique déjà rencontrée en MapReduce, mais ne nécessite pas d’écrire explicitement des tâches map et reduce :
input_lines = LOAD 'repertoire_ou_fichier' AS (line:chararray);
-- Extract words from each line and put them into a pig bag
-- datatype, then flatten the bag to get one word on each row
words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
-- filter out any words that are just white spaces
filtered_words = FILTER words BY word MATCHES '\\w+';
-- create a group for each word
word_groups = GROUP filtered_words BY word;
-- count the entries in each group
word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word;
-- order the records by count
ordered_word_count = ORDER word_count BY count DESC;
STORE ordered_word_count INTO 'repertoire_de_sortie';Programmer l’algorithme du PageRank avec Pig
On part d’un réseau de \$N\$ pages qui se citent ; ce réseau est donné par un fichier texte de la forme
12 25
34 268où chaque ligne est composée de deux éléments séparés par un \t et signifie que le premier cite le second.
Initialement toutes les pages sont affectées d’un même poids
\$w_i^0=1/N\$.
Pour chaque sommet \$i\$, on calcule le nombre \$n_i\$ de liens
i→j.
Ensuite, dans un premier mouvement, on affecte chaque sommet \$i\$ d’un nouveau poids :
\[ w_i^1 = cw_i^0+(1-c)\sum_{j\to i} \frac{w_j^0}{n_j} \]
où \$c\$ est coefficient qui est souvent pris égal à \$0.15\$ pour des raisons heuristiques. Le coefficient \$c\$ est souvent appelé "coefficient de téléportation".
On itère cet opération une dizaine de fois en posant :
\[ w_i^{n+1} = cw_i^0+(1-c)\sum_{j\to i} \frac{w_j^n}{n_j} \]