
Hadoop est un framework libre et open source écrit en Java destiné à faciliter la création d’applications distribuées (au niveau du stockage des données et de leur traitement) et échelonnables (scalables) permettant aux applications de travailler avec des milliers de nœuds et des pétaoctets de données. Ainsi chaque nœud est constitué de machines standard regroupées en grappe. Tous les modules de Hadoop sont conçus dans l’idée fondamentale que les pannes matérielles sont fréquentes et qu’en conséquence elles doivent être gérées automatiquement par le framework.
Hadoop a été inspiré par la publication de MapReduce, GoogleFS et BigTable de Google. Hadoop a été créé par Doug Cutting et fait partie des projets de la fondation logicielle Apache depuis 2009.
Le noyau d’Hadoop est constitué d’une partie de stockage : HDFS (Hadoop Distributed File System), et d’une partie de traitement appelée MapReduce. Hadoop fractionne les fichiers en gros blocs et les distribue à travers les nœuds du cluster. Pour traiter les données, Hadoop transfère le code à chaque nœud et chaque nœud traite les données dont il dispose. Cela permet de traiter l’ensemble des données plus rapidement et plus efficacement que dans une architecture supercalculateur plus classique qui repose sur un système de fichiers parallèle où les calculs et les données sont distribués via les réseaux à grande vitesse.
Le vrai Hadoop (le doudou du fils de Doug Cutting)

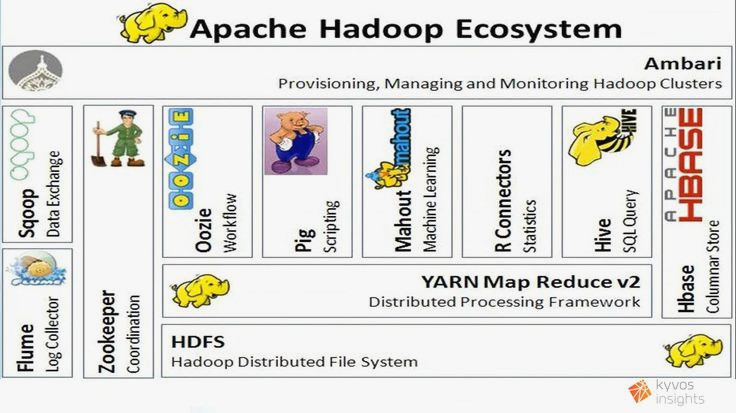
L’écosystème Hadoop
-
Un système de fichiers
-
Un ordonnanceur (ou plusieurs ordonnanceurs concurrents)
-
Des interfaces de haut niveau
-
Un système de bases de données
-
Des outils d’administration et d’échange de fichiers
L’implémentation
Hadoop est un produit open source. Il existe plusieurs distributions de Hadoop
-
La distribution originale de la fondation Apache
-
La distribution Cloudera
-
La distribution HortonWorks
-
La distribution MapR
Ces trois dernières offrent des packaging de la distribution Apache, et ont des versions commerciales et des versions lite gratuites, fonctionnant en particulier dans des machines virtuelles VirtualBox ou VMware (elles nécessitent des PC suffisamment puissants et bien dotés en RAM).
La distribution de Hadoop présente plusieurs modes :
-
Standalone : tout sur une machine de manière monolythique
-
Pseudo-distribuée : sur une machine, mais fonctionne avec différentes machines virtuelles java comme dans un cluster
-
Distribuée : les différentes machines virtuelles fonctionnent sur des machines physiques différentes.
Afin de mettre en pratique, nous avons installé sur la machine data une architecture pseudo-distribuée en utilisant la distribution originale.
Le système de fichier HDFS
-
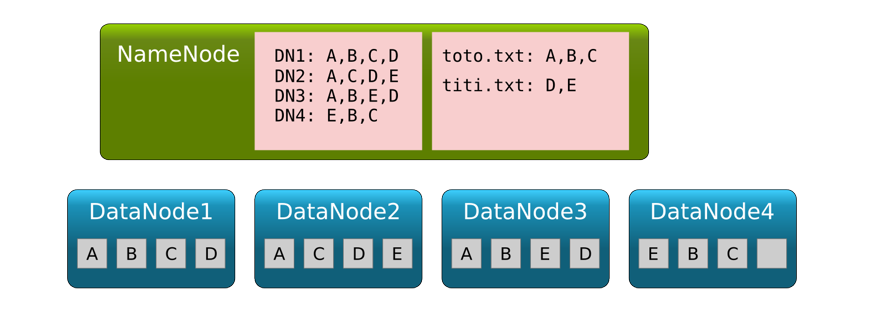
Système de fichiers réparti : plusieurs DataNodes et un Namenode (redondant)
-
Chaque fichier est découpé en blocs (64 Mo par défaut, mais peut aller jusqu’à 512 Mo).
-
Les blocs sont répartis, en plusieurs exemplaires, sur plusieurs datanodes.
-
Le NameNode gère la table qui fait correspondre à un nom de fichier la liste des emplacements des différents blocs.
-
write-once read-many (ou read-multiple-times): système adapté à un traitement batch. Pas du tout adapté à un traitement interactif.
Quelques commandes du système de fichier HDFS
hdfs dfs -ls # lister les fichiers
hdfs dfs -put fichier destination # copie système de fichier local -> hdfs
hdfs dfs -get fichier # copie hfds -> système de fichier local
hdfs dfs -cat fichier # affichage d'un fichier texte sur le terminal
hdfs dfs -mkdir repertoire # création d'un répertoire
hdfs dfs -cp ancien nouveau # copie de fichiers dans hdfs
hdfs dfs -mv ancien nouveau # déplacement ou renommage
hdfs dfs -rm fichier # supprimer un fichier
hdfs dfs -rm -f -r repertoire # supprimer un répertoireExécution des calculs sous Hadoop
L’architecture de calcul de Hadoop est basée sur un processus maitre, appelé job tracker qui s’occupe de l’ordonnancement des traitements et de la gestion de l’ensemble des ressources du système.
Le client lui envoie des tâches MapReduce, les données d’entrée et le répertoire de sortie.
Le Job Tracker est en communication avec le name node d’HDFS. Il planifie l’exécution des tâches et les distribue à des processus appelés task trackers.
Le task tracker lance une machine virtuelle java (JVM) qui exécute des tâches de MAP, REDUCE ou SHUFFLE.
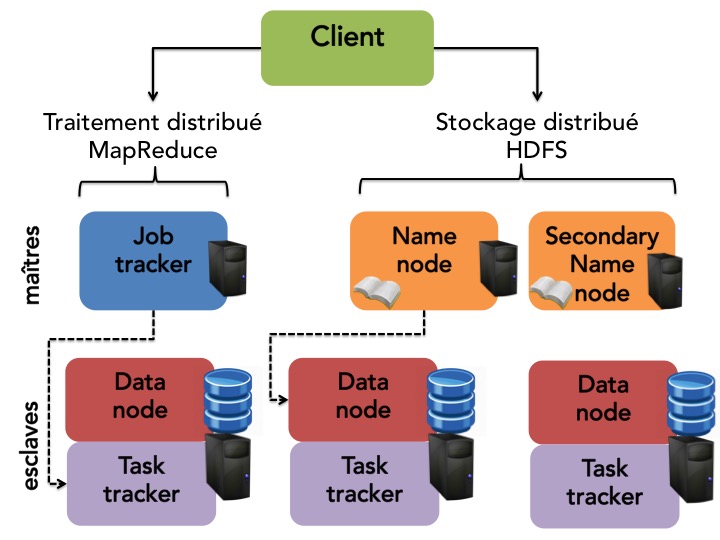
Dans les version 2.x et 3.x de Hadoop, on a introduit un ordonnanceur de plus haut niveau, appelé yarn, permettant de faire exécuter des programmes non simplement écrits suivant le paradigme map-reduce. Dans ce cas, c’est yarn qui traduit le programmes en tâches map-reduce.
Expérimentation de Hadoop et HDFS
Pour tester les technologies hadoop, nous avons mis en place sur le serveur data une implémentation de hadoop, qui fonctionne en mode "pseudo-distribué" : il y
a une seule machine, mais elle fait fonctionner les processus
exactement comme si ils étaient répartis sur plusieurs
machines.
Chacun (datanode, namenode, jobtracker, tasktracker,ordonnanceur yarn) correspond à
une machine virtuelle java séparée.
On verra que chacune des tâches qu’on lance demande le lancement d’un certain nombre de machines virtuelles, ce qui entraine un temps de latence important. Pour un programme élémentaire, hadoop semble particulièrement peu performant. Il faut donc garder à l’esprit que le but et la force de Hadoop est de travailler avec des données de très grande taille, et de pouvoir s’adapter à la taille des ces données.
On se connecte à la machine data par ssh ; on a alors accès à
son répertoire unix ordinaire. On interagit avec le système uniquement en ligne de commandes.
L’espace hdfs contient un répertoire /user, avec un sous
répertoire ayant pour nom le login de chaque utilisateur. Par défaut,
les commandes de manipulation de fichiers que lancera l’utilisateur toto par
hdfs se feront dans son répertoire /user/toto.
Pour aller plus loin, on va faire tourner des programmes utilisant
l’infrastructure hadoop. Un programme écrit pour map-reduce est écrit
sous forme d’une archive jar. Cela impose de programmer en
java. Ici, on va juste en tester, puis voir comment on peut utiliser
hadoop pour faire tourner des programmes python.
On va ensuite tester nos programmes map.py et reduce.py qui réalisent le wordcount en utilisant
l’interface streaming de hadoop, qui permet d’utiliser des programmes
écrits dans d’autres langages que java.
On dispose de deux fichiers :
map.py#!/app/anaconda/latest/bin/python
import sys
import re
motif=re.compile("\w+")
for ligne in sys.stdin:
for mot in motif.findall(ligne.strip().lower()):
print(f"{mot}\t1")et
reduce.py#!/app/anaconda/latest/bin/python
import sys
cle_prec,nb_total = None,0
for ligne in sys.stdin:
cle, valeur = ligne.split('\t', 1)
if cle == cle_prec:
nb_total += int(valeur)
else:
if cle_prec != None:
print(f"{cle_prec}\t{nb_total}")
cle_prec = cle
nb_total = int(valeur)
if cle_prec != None:
print(f"{cle_prec}\t{nb_total}")