-
Extract
-
Transform
-
Load
ETL désigne l’ensemble du processus qui part de l’extraction de données depuis différentes sources, qui nettoie et transforme ces données, puis les charge dans un système de données structuré.
Ci joint un schéma proposé par l’un des principaux acteurs du marché, la société Informatica, qui décrit l’ensemble du processus de traitement des données.
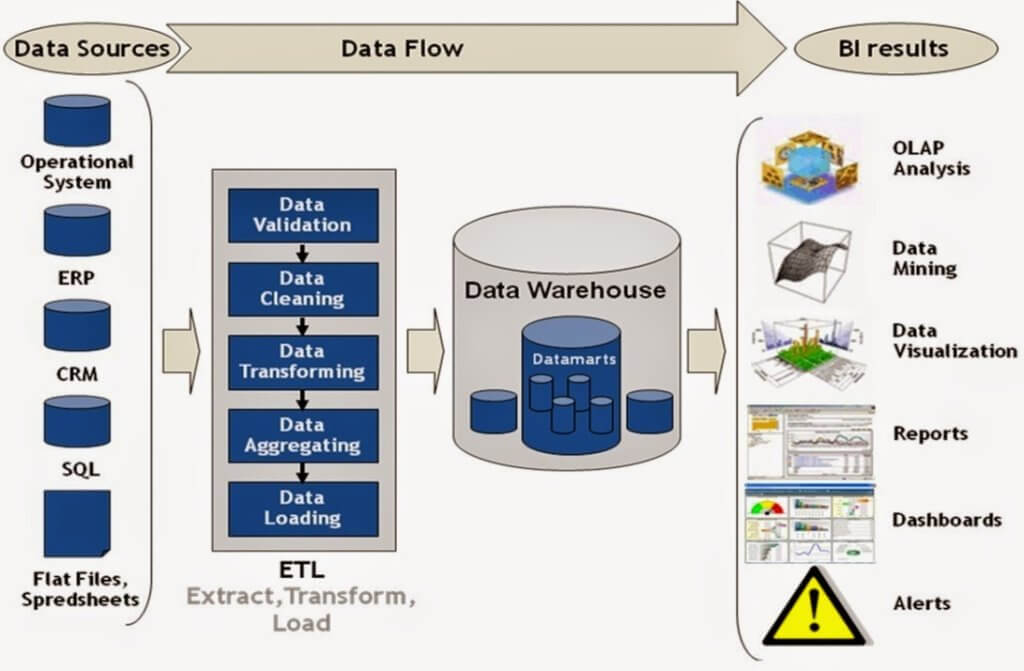
ETL vs ELT
Notons que dans l’optique du traitement de données de très grandes tailles (big data), on utilise du stockage de données de type NoSQL, par exemple les environnements hadoop ou spark. Ces environnements stockent les données sous forme peu structurées dans un espace de stockage distribué (qu’on appelle, quand on veut faire branché, un "data lake").
Dans ce cas l’ensemble du processus de traitement suit le schéma ELT :
-
E - Les données sont extraites des différentes sources
-
L - Elles sont chargées en l’état dans le data lake.
-
T - C’est l’infrasture de stockage qui est chargée de traiter les données.
Les outils ETL
On peut dire que les méthodes qu’on a utilisées avec python et pandas sont des techniques d’ETL, mais devant l’importance grandissante de cette tâche, il a été développé des outils spécifiques.
On trouve différents types d’outils
-
Des outils cloud
-
Des outils proprétaires installés sur les machines locales
-
Informatica : le leader du marché, et de loin le plus cher
-
IBM Infosphere
-
les outils SAS
-
-
Des outils libres installés sur les machines locales
-
Talend
-
Apache Airflow
-
Apache Kafka
-
Cloudera DataHub
Ces trois derniers outils sont plus particulièrement adaptés aux solutions NoSQL. On peut dire aussi que des outils comme pig, hive ou spark font aussi de l'ELT.
-
La solution Talend
Les outils Talend sont libres (licence Apache), et distribués par la société Talend, qui vend des extensions proprétaires et du service.
Talend Open Studio est téléchargeable sur https://sourceforge.net/projects/talend-studio/
TOS est un ensemble de composants java, basé sur le framework Eclipse. Le principe est de décrire des flux de données, représentés par différents composants qu’on enchaîne de façon graphique, comme par exemple :
ou
Voici un liste de quelques composants qu’on peut enchaîner :
tPostgresqlConnection − Connects to PostgreSQL database defined in the component. Même chose pour les autres SGBD.
tPostgresqlInput − Runs database query to read a database and extract fields (tables, views etc.) depending on the query.
tPostgresqlOutput − Used to write, update, modify data in a PostgreSQL database.
tFileInputDelimited − Reads a delimited file row by row and divides them into separate fields and passes it to the next component.
tFileInputExcel − Reads an excel file row by row and divides them into separate fields and passes it to the next component.
tFileList − Gets all the files and directories from a given file mask pattern.
tFileArchive − Compresses a set of files or folders in to zip, gzip or tar.gz archive file.
tRowGenerator − Provides an editor where you can write functions or choose expressions to generate your sample data.
tMsgBox − Returns a dialog box with the message specified and an OK button.
tLogRow − Monitors the data getting processed. It displays data/output in the run console.
tPreJob − Defines the sub jobs that will run before your actual job starts.
tMap − Acts as a plugin in Talend studio. It takes data from one or more sources, transforms it, and then sends the transformed data to one or more destinations.
tJoin − Joins 2 tables by performing inner and outer joins between the main flow and the lookup flow.
tJava − Enables you to use personalized java code in the Talend program.
tRunJob − Manages complex job systems by running one Talend job after another.
Une petite Démo
Pour aller plus loin, on va faire une démonstration, en espérant que la technique suive…
On commence par lancer le logiciel, attendre un long moment, puis ouvrir un projet.

Ensuite on crée un job
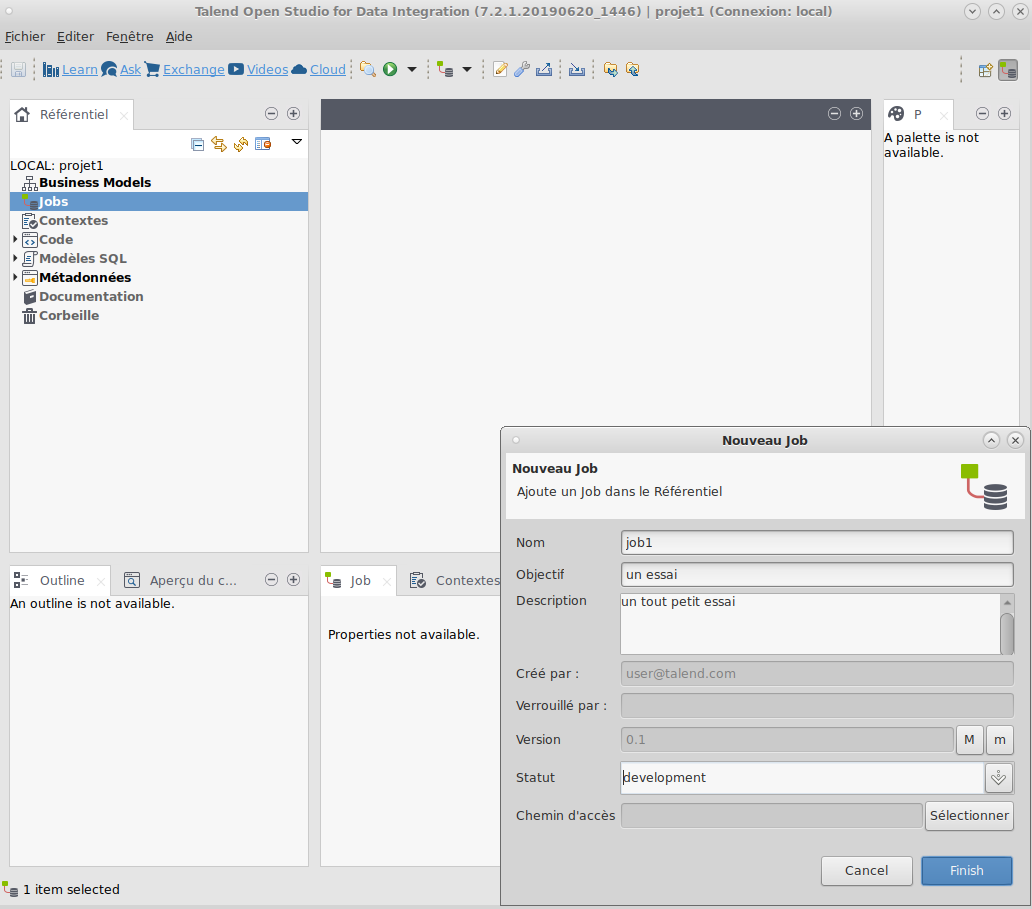
On se retrouve devant un espace de travail
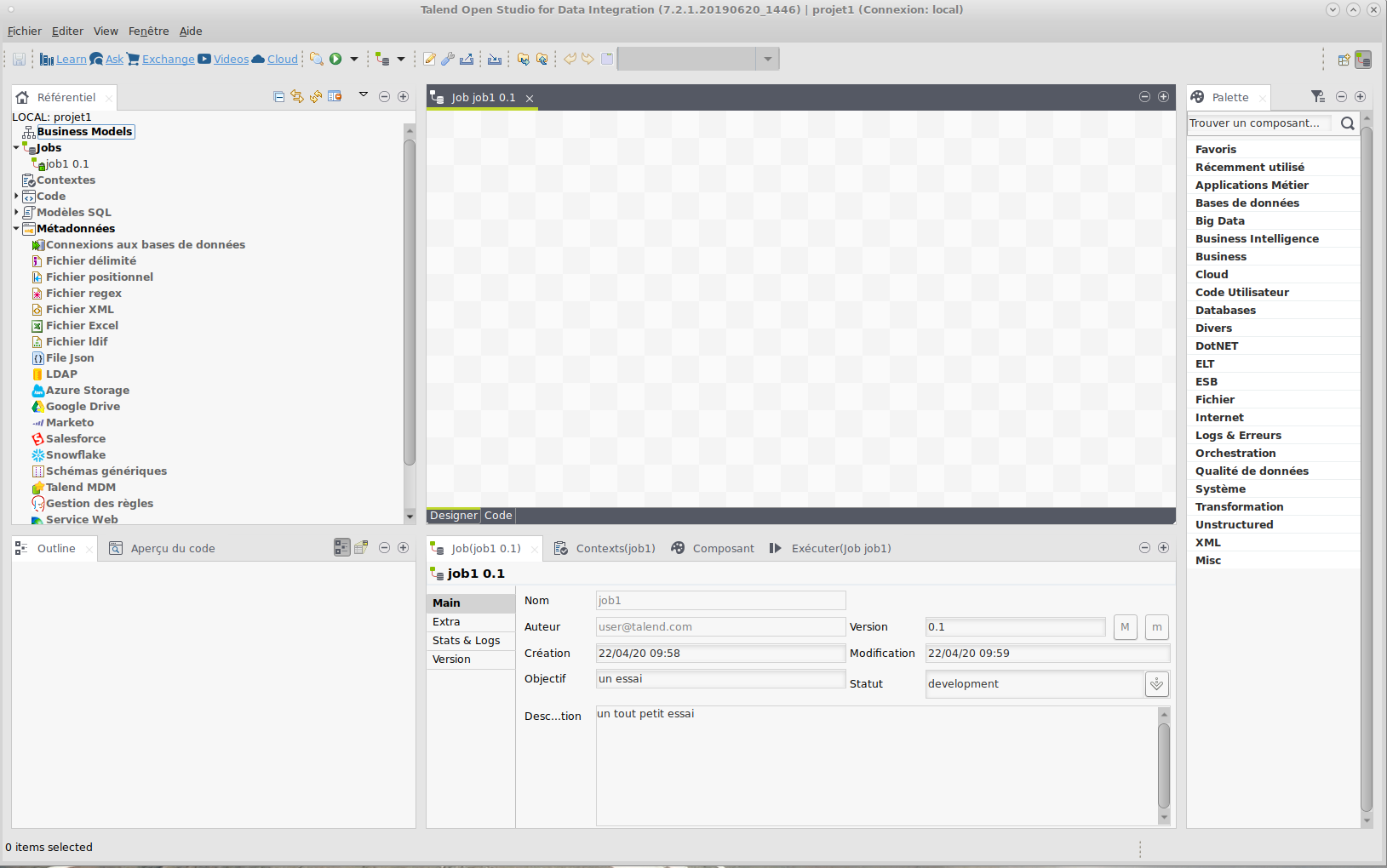
On distingue
-
la zone de gauche est le référentiel (repository), qui contient les différentes méthodes de connexion qu’on définira,
-
celle de droite (palette) contenant les composants qu’on va assembler,
-
la zone centrale est l’espace de modélisation (Design workspace) où l’on assemble les différents composants,
-
la zone en dessous servant à paramétrer les composants, et à lancer l’exécution des jobs,
-
la zone en bas à gauche qui contient des modèles de code (Outline view et Code Viewer)
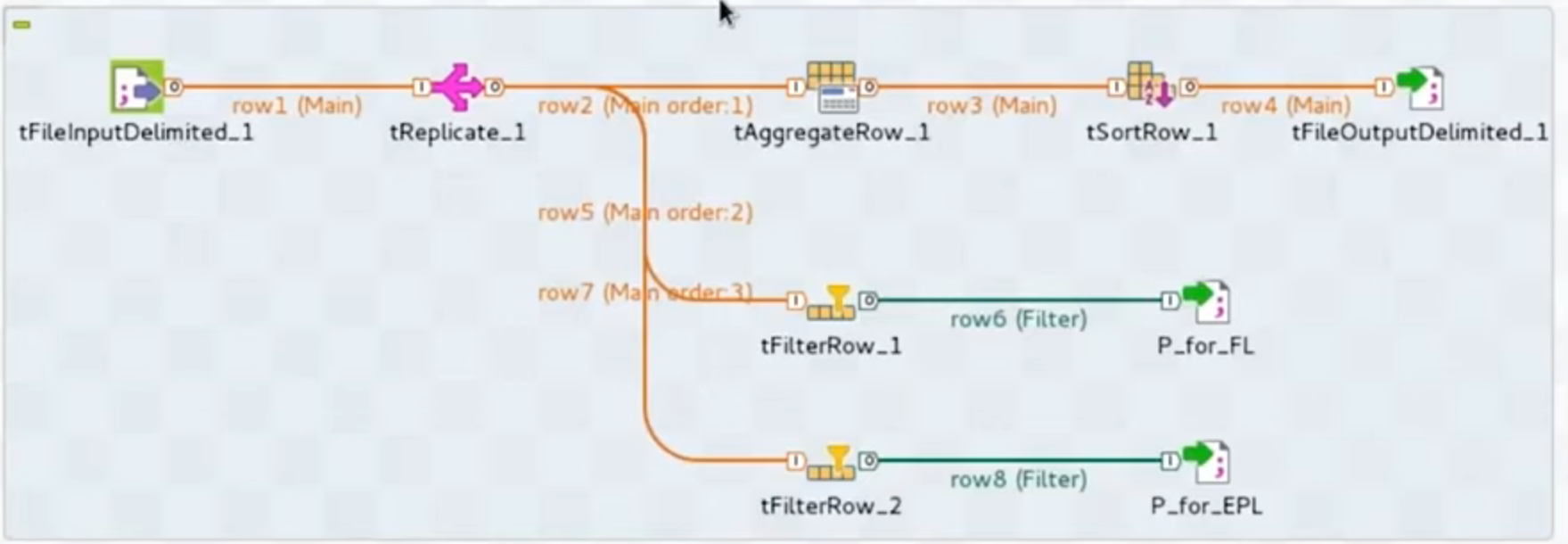
Voici un job, qui prend en entrée un fichier délimité (fichier plat, dont les champs sont séparés par un délimiteur) et effectue 3 traitements différents sur les lignes de ce fichier, puis stocke les résultats dans des fichiers délimités.
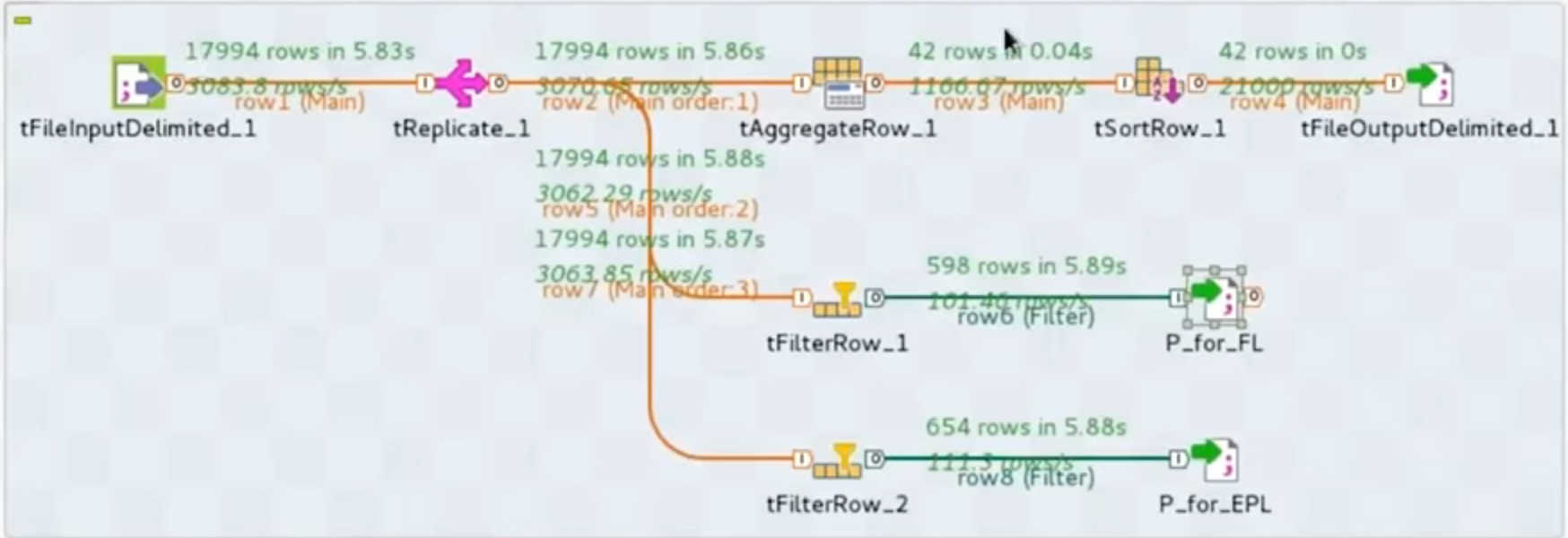
Une fois le job effectué, on voit s’afficher les différentes lignes qui sont passées dans le flux de données :
dans ces exemples, on n’a regardé que des flux de données provenant de, ou allant vers un fichier avec délimiteur, mais tous les types de stockage de données sont possibles :
-
XML
-
JSON
-
fichiers Excel
-
base de données relationnelles
-
stockage NoSQL
-
etc.
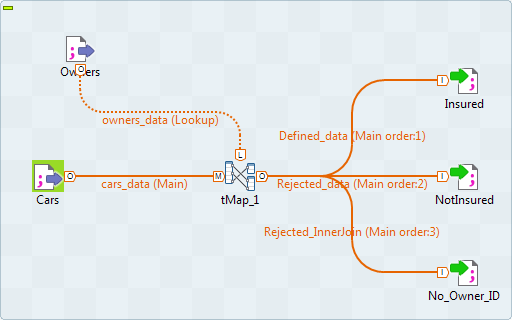
Voici ici l’interface de paramétrage de l’outil tmap qui sert à effectuer des jointures entre deux flux de données :
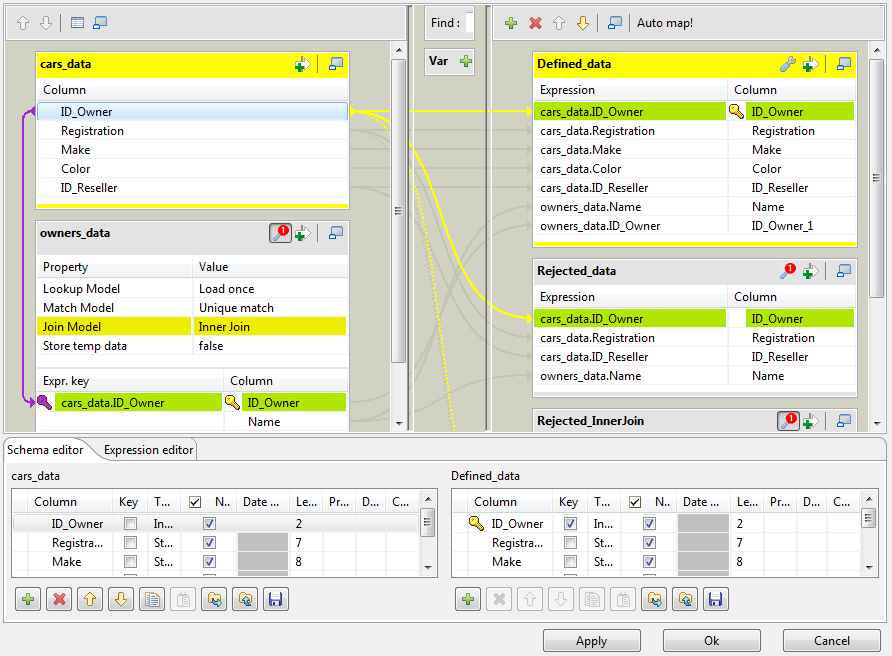 On voit à gauche les deux flux de données et on voit représentée par la flèche violette la condition de jointure sur la clé Id_Owner. Enfin, on voit à droite les sorties de la jointure.
On voit à gauche les deux flux de données et on voit représentée par la flèche violette la condition de jointure sur la clé Id_Owner. Enfin, on voit à droite les sorties de la jointure.
Références
Pour ceux qui voudraient une présentation assez détaillée, voici un cours d’introduction à Talend, sous forme d’une une vidéo de 6h : https://www.youtube.com/watch?v=bqa0kB59SUc
J’y ai appris pas mal de choses, même si il faut ensuite pratiquer.
On peut aussi regarder l’aide en ligne