La partie TP de cette feuille fera usage du logiciel de modélisation comme SQL Power Architect ou pgmodeler ; si vous travaillez sur votre propre machine, il est conseillé d’installer un tel logiciel. De même, il pourra être intéressant d’utiliser un logiciel de dessin technique, comme draw.io, pour réaliser des diagrammes conceptuels.
0. Introduction
On veut stocker dans un système de données les informations sur des films. On peut envisager de tout mettre dans une table :
| titre | annee | nomReal | prenomReal | anNaiss |
|---|---|---|---|---|
Alien |
1979 |
Scott |
Ridley |
1943 |
Vertigo |
1958 |
Hitchcock |
Alfred |
1899 |
Psychose |
1958 |
Hitchcock |
Alfred |
1899 |
Une telle représentation n’est pas satisfaisante. Pourquoi ?
I. Le modèle entité-association
On regarde un journal de critique de cinéma, qui tient à jour une base pour stocker des informations :
-
Un film a été tourné à une date, dans un pays, par un réalisateur, avec des acteurs, et relève d’un ou plusieurs genres
-
Un acteur, comme un réalisateur a différents éléments biographiques, et il a une nationalité
-
des internautes, qui ont différentes coordonnées notent les films en donnant des appréciations, à des dates données.
Pour décrire ces données, on va distinguer différents types d’entités :
-
Artiste
-
Film
-
Genre
-
Pays
-
Internaute
-
Recommandation
Une entité a différents attributs naturels. Par exemple chaque entité de type Film a des attributs, parmi lesquels, on peut citer : titre, annee, genre, resume.
On représente généralement une entité graphiquement par un bloc :

Il faut bien comprendre que l’entité film n’est pas un objet. C’est le concept de film. Un film donné sera une instance de cette entité. En programmation objet, une entité serait une classe, et une instance serait un objet.
|
Les différentes identités sont reliées par des associations. Ainsi :
-
Chaque artiste a exactement un pays (à moins de considérer des apatrides, ou au contraire des binationaux)
-
Certains artistes interviennent comme acteurs dans plusieurs films.
-
Chaque film a exactement un réalisateur (à moins de considérer des co-réalisations).
On représente une association par un diagramme
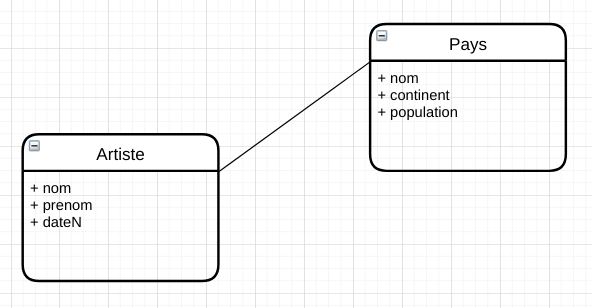
| Une association entre deux entités A et B est une correspondance entre des instances de A et des instances de B |
Asociations ternaires ou plus
Des associations peuvent relier plus de deux entités. Voilà par exemple une association ternaire :
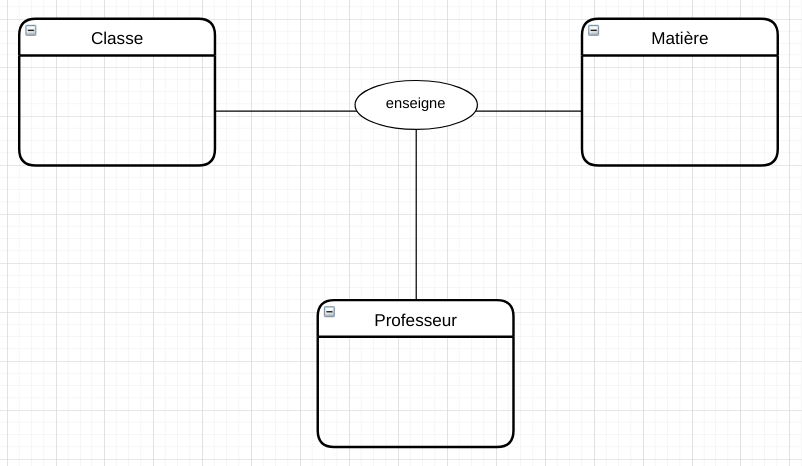
De même, pour modéliser le fonctionnement d’un cinéma, on peut de même envisager une association entre quatre entités :
-
Film
-
Billet
-
Salle
-
Horaire
Différents types d’association
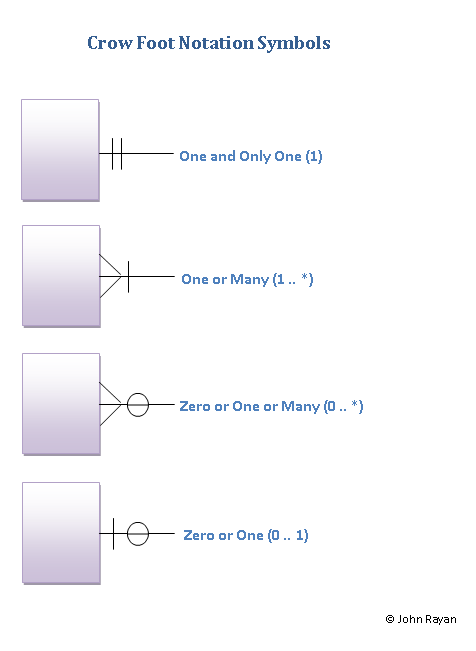
Une association entre deux entités a une cardinalité :
"Un livre a un ou plusieurs auteurs"
"Un code pays correspond exactement à un pays"
On utilise pour représenter ces cardinalités des codes graphiques. L’un d’entre eux est la notation en "pattes de corbeau" :
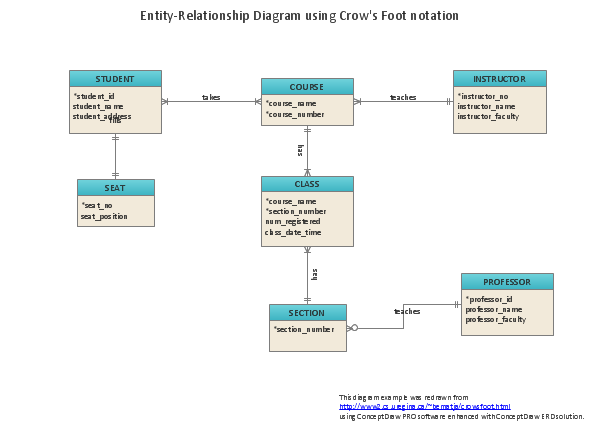
Voici un diagramme utilisant cette notation :
Entités fortes /entités faibles
-
Pour gérer l’activité d’un site de commandes en ligne, on peut considérer des entités :
facture : id_facture, date, montant
ligne_commande : id_ligne, quantite, produitIci une ligne de commande est reliée à une facture. Mais on peut envisager que dans l’historique du traitement des commandes, une ligne soit rattachée à une autre facture.
La ligne de commande a son existence propre. On parle d’entité forte.
-
Un site de réservation de chambres d’hôtel tient un état des chambres disponibles
hotel : id_hotel, adresse, nb_etoiles
chambre : no_chambre, id_hotel, nb_lits, expositionIci, une chambre n’a pas d’existence propre indépendamment de l’hôtel. Ce qui identifie la chambre, c’est le couple (no_chambre, id_hotel).
Dans ce cas, on parle d’entité faible ou bien on dit que l’association chambre-hôtel est identifiante.
II. Du modèle entité-association à sa représentation relationnelle.
Définir des tables
Une base de données relationnelles est constituées de différentes tables, chacune décrivant une relation.
Il est facile de concevoir qu’à une entité, on va associer une table. Les colonnes de la table correspondront aux attribut de l’entité.
Il serait souhaitable qu’une entité ait un attribut qui la caractérise de manière unique. Revenons à l’entité Film ; on peut envisager de prendre comme clé unique le titre, mais il est aussi possible que deux films aient le même titre. On préfère donc rajouter un identifiant numérique :
Film : [id, titre, annee, genre, resume]
Traduire les associations
Il reste ensuite à réaliser le codage des associations en termes de tables :
-
Une association many-to-one entre une entité A et une entité B se code en mettant dans la table A un champ référençant l’identifiant de l’entité B
Par exemple, pour l’association une facture correspond à plusieurs lignes de commande, on indiquera dans chaque enregistrement d’une ligne de commande la référence à la facture correspondante. On va donc avoir un schéma de tables :
factures(id_facture, date, montant)
lignes_commande(id_ligne, quantite, produit, id_facture)-
Une association many-to-many entre deux entités, représentées par des tables
AetB, se code en introduisant une troisième tableA_B, dite table de liaison. Chaque enregistrement de la tableA_Bcontient un identifiant d’une ligne deAet un identifiant d’une ligne deB, avec éventuellement des informations supplémentaires sur l’association entre les deux enregistrements.
Ainsi, si on veut stocker des informations sur des films et des acteurs, on va considérer :
Films(id_film, titre, date, duree)
Acteurs(id_acteur, nom, prenom, date_naissance, pays)
Films_acteurs(id_film, id_acteur, role)Imposer des contraintes
Une base de donnée n’est pas simplement un ensemble de tables, mais aussi un ensemble de mécanismes directement gérés par le SGBD, destinés à assurer l’intégité et la cohérence des données. On parle de "contraintes d’intégrité".
Clé primaire
Une clé primaire pour une table est un attribut, ou un groupe d’attributs, qui définit de manière unique chaque enregistrement de la table. La clé primaire doit être définie pour tout enregistrement de la table, et il ne doit pas exister deux enregistrements ayant la même clé primaire.
Une table a au plus une clé primaire, et il est recommandé de définir une clé primaire pour toute table.
Contrainte d’unicité
D’autres attributs que la clé primaire peuvent également avoir une contrainte d’unicité, mais peuvent ne pas être remplis.
Clés étrangères
Une clé étrangère de la table A identifie une colonne ou un ensemble de colonnes de A comme référençant une colonne ou un ensemble de colonnes d’une autre table B (la table référencée). Les colonnes de la table B référencées par cette clé primaire doivent faire partie de la clé primaire de B.
Dans l’exemple
factures(id_facture, date, montant)
lignes_commande(id_ligne, quantite, produit, id_facture)on peut définir id_facture comme clé étrangère de lignes_commande, référençant factures.
Dans ce cas, le SGBD refusera de créer une ligne de commande si le numéro de facture n’est pas déjà défini dans la table factures. Il reste à définir ce qui se passe lorsque, une fois qu’on a fait un tel enregistrement d’une facture et d’une ligne de commande la référençant, on modifie la table facture par exemple
-
en modifiant des informations
-
en supprimant un enregistrement.
On eut envisager que le SGBD bloque l’opération, ou bien au contraire supprime toutes les lignes de la table lignes_commande référençant la ligne supprimée de factures.
On verra comment définir ces comportements dans le langage SQL.
Contrainte de non nullité
On peut imposer que dans tous les enregistrements d’une table, un champ donné soit toujours rempli. Dans ce cas, si on entre un nouvel enregistrement sans renseigner le champ requis, le SGBD provoque une erreur. Le mot clé est NOT NULL.
Imposer qu’une condition soit vérifiée
On peut imposer qu’une condition soit vérifiée lors de l’insertion d’un enregistrement. En revanche, il n’est pas évident de savoir ce que fait le SGBD en cas de modification d’un enregistrement. C’est le mot clé CHECK qui sera utilisé pour imposer des conditions.
III. Créer une base de données avec les commandes SQL
Création d’une table
La commande de base est CREATE TABLE, dont la syntaxe est
CREATE TABLE matable(
champ_1 type_du_champ_1 propriété_du_champ1,
...
champ_n type_du_champ_n propriété_du_champ_n,
CONSTRAINT nom_contrainte_1 description,
...
CONSTRAINT nom_contrainte_p description
)Par exemple, on crée une table films, avec des champs id_film, titre, id_distrib, date_prod, genre , dont le premier est une clé rimaire et les deux suivants doivent impérativement être renseignés :
CREATE TABLE films (
id_film char(5) PRIMARY KEY,
titre varchar(40) NOT NULL,
id_distrib integer NOT NULL,
date_prod date,
genre varchar(10)
);ou une variante, où on préfère définir séparément la contrainte de clé primaire, en lui donnant un nom
CREATE TABLE films (
titre varchar(40),
date_prod date,
id_distrib integer NOT NULL,
CONSTRAINT titre_date PRIMARY KEY(titre,date_prod)
);Gestion des clés étrangères
On veut associer à chaque film un distributeur :
CREATE TABLE distributeurs (
id_distrib integer PRIMARY KEY ,
nom varchar(40)
);
CREATE TABLE films (
id_film char(5) PRIMARY KEY,
titre varchar(40) NOT NULL,
id_distrib integer NOT NULL,
CONSTRAINT fk_film_distrib FOREIGN KEY id_distrib REFERENCES distributeurs(id_distrib)
);La clause de clé étrangère peut être complétée en indiquant quel comportement doit adopter le SGBD lorsqu’une opération de modification ou de destruction viole la contrainte de clé étrangère :
FOREIGN KEY nom_cle REFERENCES nom_table ON DELETE action ON UPDATE actionoù l’action peut être :
-
RESTRICT: Une erreur est produite pour indiquer que la suppression ou la mise à jour entraîne une violation de la contrainte de clé étrangère. -
CASCADE: La mise à jour ou la suppression de la ligne de référence est propagée à l’ensemble des lignes qui la référencent, qui sont, respectivement, mises à jour ou supprimées. -
SET NULL: La valeur de la colonne qui référence est positionnée à NULL. -
SET DEFAULT: La valeur de la colonne qui référence est positionnée à celle par défaut.
Les contraintes CHECK
Le mot clé CHECK permet d’imposer que lors de l’insertion d’un enregistrement, un champ vérifie une propriété.
CREATE TABLE products (
product_no integer,
name text,
price numeric CONSTRAINT positive_price CHECK (price > 0)
);ou en portant sur plusieurs colonnes :
CREATE TABLE products (
product_no integer,
name text,
price numeric CHECK (price > 0),
discounted_price numeric CHECK (discounted_price > 0),
CHECK (price > discounted_price)
);Comment se comporte la condition CHECK lors des opérations de modification est beaucoup moins clair.
Ajout d’une contrainte à une table avec SQL
Dans la pratique, on crée souvent les tables dans un premier temps, et on indique les contraintes liées aux associations, dans un second temps. Dans ce cas, on va utiliser ALTER TABLE
ALTER TABLE table_1 ADD CONSTRAINT table1_table2_fk FOREIGN KEY (colonne_1)
REFERENCES table_2 (colonne_2)
ON DELETE SET NULL ON UPDATE CASCADE;
ALTER TABLE table_1 ADD CONSTRAINT table_1_uq UNIQUE (une_colonne);Les index
Plusieurs types d’opérations nécessitent un accès rapide aux données dans une ou plusieurs colonnes.
L’accès à cette colonne peut être séquentiel : on parcourt successivement chacun des enregistrements jusqu’à avoir la réponse. Cette méthode d’accès est forcément lente.
On peut aussi mettre sur cette colonne une structure d’index, permettant une recherche par un algorithme plus rapide, par exemple une recherche dichotomique. Un index est basé, sur plusieurs techniques, comme les tables de hachage, ou les B-Trees.
Si l’existence d’un index accélère les opérations de recherche sur une colonne, elle pénalise les opérations d’écriture. Il n’est donc pas justifié de créer des index si on n’en a pas un besoin précis.
En SQL, on définit un index de la façon suivante :
CREATE INDEX nom_index ON matable(colonne_1,colonne_2,...)En particulier, lorsqu’on crée une contrainte de clé primaire ou une contrainte d’unicité, le SGBD crée automatiquement un index pour lui permettre d’effectuer les vérifications liées à la contrainte. Il n’y a donc pas à demander soi même la création de l’index dans ce cas.
Les colonnes auto-incrémentées
Pour une colonne destinée à servir de clé primaire technique (sans signification particulière, mais assurant la contrainte de clé primaire), il peut être intéressant d’avoir une colonne qui se remplit d’elle même lors des insertions, en s’autoincrémentant. Dans certains SGBD, on utilise le mot clé
AUTO_INCREMENT.
PostgreSQL propose un type particulier (des entiers qui s’autoincrémentent), en trois versions
-
SERIALentiers sur 4 octets (32 bits) -
SMALLSERIALentiers sur 2 octets (16 bits), si on est certains de ne pas dépasser 32767 lignes -
BIGSERIALentiers sur 8 octets (64 bits), si on a un nombre de lignes gigantesque
La création d’une colonne autoincrémentée induit la création automatique par PostgreSQL d’un objet appelé SEQUENCE, qui est un peu l’équivalent d’un générateur en python. On peut aussi créer par soi même une séquence, puis l’itiliser dans une autre table.
CREATE SEQUENCE masequence START 101;Si on fait une requête
SELECT nextval('masequence');on obtient 101, et si on refait cette requête, le serveur nous rend 102.