Les fonctions map, reduce et filter de la programmation fonctionnelle
Le principe de la programmation fonctionnelle est de n’écrire que des fonctions, et d’enchainer ces fonctions. On évite ainsi de faire appel à des variables globales, ce qui minimise les problèmes d'effet de bord (une variable est modifiée par un programme A, et cela influe sur le comportement d’un autre programme B, sans que l’auteur de B en soit conscient).
def avec_effet_bord(A) :
# A est une liste
A[-1] = "*"
return(A)
def sans_effet_bord(A) :
# A est une liste
B = [a for a in A]
B[-1] = "*"
return(B)
L1 = [1,2,3]
L1_bis = avec_effet_bord(L1)
print(L1)
print(L1_bis)
L2 = [1,2,3]
L2_bis = sans_effet_bord(L2)
print(L2)
print(L2_bis)La programmation fonctionnelle est une idée ancienne en informatique qui a été à la naissance de langages tels que LISP. Voici un exemple de code LISP (moyennement lisible !) :
(defun factorial (n &optional (acc 1))
"Calcule la factorielle de l'entier n."
(if (<= n 1)
acc
(factorial (- n 1) (* acc n))))En Python, la programmation fonctionnelle s’appuie essentiellement sur les itérateurs et la fonction map.
La fonction map
La fonction map applique une fonction à un objet itérable et rend un itérateur.
carre = lambda t:t*t
n = 15
x = map(carre,range(n))Vérifier que l’objet x ainsi construit est bien un itérateur
x = map(carre,range(n))
l = [carre(i) for i in range(n)]Comparer les empreintes mémoires des objets x et l en utilisant la fonction getsizeof du module sys
La fonction filter
La fonction filter filtre un objet itérable suivant le résultat d’une fonction à valeurs booléenne.
f1 = lambda t:t%2==0
x = map(carre,range(n))
y = filter(f1,x)Que fait la fonction f1 ?
Que va contenir l’objet y ?
Bien sûr, on peut tout grouper en une commande, plus ou moins lisible :
y = filter(lambda t:t%2==0, map(lambda t:t*t , range(15)))La fonction reduce
La fonction reduce s’applique à un objet itérable pour le réduire en appliquant successivement aux termes de cet objet une fonction binaire (qui prend deux paramètres en entrée). Par exemple, soit f une fonction binaire renvoyant un seul résultat, reduce(f,[a,b,c,d]) va calculer f(f(f(a,b),c),d).
from functools import reduce
f2 = lambda t,u: t+u
x = map(carre,range(n))
y = filter(f1,x)
z = reduce(f2,y)
print(z)Que fait la fonction f2 ?
Que va contenir l’objet z ?
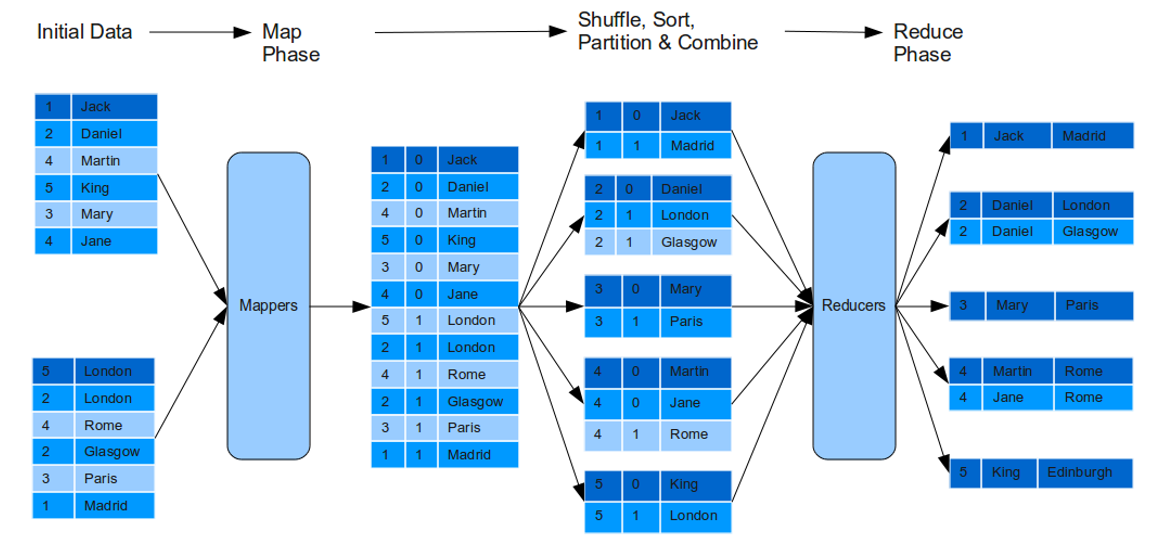
Le principe général de Map-Reduce
Le paradigme map-reduce a été introduit en 2004 par des ingénieurs de Google dans l’article : https://research.google.com/archive/mapreduce-osdi04.pdf. Il reprend des idées bien connues de la programmation fonctionnelle en les appliquant à du calcul massivement parallèle.
-
Données d’entrée sous forme d’une collection clé-valeur, qui seront éventuellement réparties sur plusieurs machines.
-
Mapper : programme qui prend un couple clé-valeur et rend une liste de couples clé-valeur
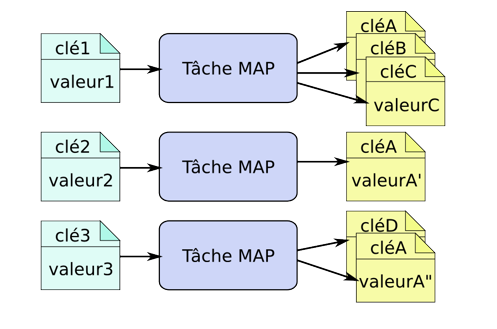
-
Shuffle and Sort : étape gérée entièrement par le système hadoop ; les couples clé-valeur produits par les différentes instances du mapper et qui correspondent à une même clé sont regroupés et envoyés à une même machine sous la forme
clé:[valeur_1,…,valeur_n]. -
Reducer : les données regroupées par l’étape shuffle sont traitées et rendent un couple clé-valeur qui est écrit dans un fichier.
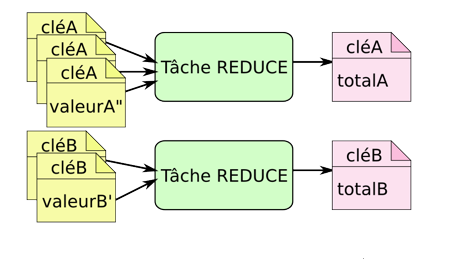
-
Plusieurs phases map-reduce peuvent être enchaînées, et il peut y avoir des reducer partiels (combiner) qui font la tâche du reducer sur la partie des données auxquelles ils ont accès.
Dans la solution proposée, on notera qu’on utilise fortement le fait que l’entrée est déjà triée (étape shuffle and sort), et que sans ce tri préalable le résultat sera beaucoup moins intéressant.
Ce que nous venons de faire est juste une démonstration de la faisabilité d’un algorithme basé sur des fonctions map et reduce. Elle n’est pas du tout utilisable dans la pratique car sous cette forme, tout tourne dans un unique processus, et n’est pas parallélisable.
La bibliothèque mrjob de python
mrjob a été développé par la société Yelp, qui publie des avis participatifs sur les commerces locaux ; pour ce travail, elle doit gérer une très grosse quantité d’avis et en extraire des statistiques. La bibliotèque mrjob est prévue pour lancer des commandes map-reduce sur un cluster hadoop local, ou sur un cloud comme AWS de Amazon. Elle permet aussi un traitement en local, uniquement en python, afin de permettre la mise au point des algorithmes. C’est ce mode que nous allons utiliser ici.
On peut trouver ici
https://www.youtube.com/watch?v=txT_sA1malk
une vidéo d’une conférence donnée au PyCon 2014, par Jim Blomo, un des créateurs de mrjob, où il explique un certain nombre de choses sur ce package.
Une documentation sur mrjob est disponible ici.
Par défaut, un programme mrjob consiste en une classe, qui hérite de la la classe MRJob et qui contient au moins deux méthodes mapper et reducer.
Le programme contient aussi une partie if name == 'main': pour exécuter la classe.
Dans l’exemple indiqué ici, le combiner est exactement le même que le reducer, mais cela n’a aucune raison d’être le cas en général.
| Le combiner doit être utilisé uniquement avec des fonctions commutatives et associatives. |
Soit un (petit) échantillon X que nous allons insérer dans le fichier texte suivant :
0
1
2
3
4Le programme suivant calcule la moyenne d’un échantillon par deux algorithmes de type map-reduce : l’un utilise un combiner, l’autre non.
#! /usr/bin/env python3
from mrjob.job import MRJob
class moyenne_sansCombiner(MRJob):
def mapper(self, _, x):
yield _, float(x)
def reducer(self, _, valeurs):
L_valeurs = list(valeurs)
yield "Moyenne (sans combiner) : ", f"{sum(L_valeurs)/len(L_valeurs):.3f}"
class moyenne_avecCombiner(MRJob):
def mapper(self, _, x):
yield _, float(x)
def combiner(self, _, valeurs):
L_valeurs = list(valeurs)
yield _, sum(L_valeurs)/len(L_valeurs)
def reducer(self, _, valeurs):
L_valeurs = list(valeurs)
yield "Moyenne (avec combiner) : ", f"{sum(L_valeurs)/len(L_valeurs):.3f}"
if __name__ == '__main__':
moyenne_sansCombiner.run()
moyenne_avecCombiner.run()On peut enregistrer les résultats de ces fonctions dans un fichier texte :
python exemples_combiner_mrjob.py sample_X > test_combiner.outPouvez-vous prédire avec certitude les résultats obtenus par ces deux fonctions ? Pourquoi ?
Un mapreduce avec plusieurs étapes
Pour des applications moins élémentaires que le simple wordcout, il faudra envisager un programme combinant plusieurs étapes de mapreduce. Dans ce cas, il faudra définir plusieurs opérateurs map et reduce et décrire un schéma d’opération indiquant l’ordre des commandes. Voici l’allure d’un tel programme ayant deux étapes, l’une comprenant un mapper, un combiner et un reducer, et l’autre ayant seulement un reducer :
from mrjob.job import MRJob
from mrjob.step import MRStep
class MaClasse(MRJob):
def mapper1(self, cle, valeur):
# traitement mapper
yield cle_m1, valeur_m1
def combiner(self, cle, valeurs):
# traitement combiner
yield cle_c, valeur_c
def reducer1(self, cle, valeurs):
# traitement reducer1
yield cle_r1, valeur_r1
def reducer2(self, cle, valeurs):
# traitement reducer2
yield cle_r2, valeur_r2
def steps(self):
return [
MRStep(mapper=self.mapper1,
combiner=self.combiner1,
reducer=self.reducer1),
MRStep(reducer=self.reducer2)
]
if __name__ == '__main__' :
MaClasse.run()Compléments sur MapReduce
Les jointures avec MapReduce
Les jointures sont à la base du travail avec des BDD relationnelles. Le schéma général est :
SELECT * FROM table1, table2 WHERE table1.attribut1 = table2.attribut2Il s’agit d’une opération très couteuse en mémoire, mais qui reste indispensable, même dans un cadre NoSQL. On peut l’éffectuer par une opération de map-reduce, suivant le schéma :